Effects of tDCS on the attentional blink revisited: A statistical evaluation of a replication attempt
Leon C. Reteig
1,2Lionel A. Newman
1,3K. Richard Ridderinkhof
1,2Heleen A. Slagter
1,4h.a.slagter@vu.nl
- Department of Psychology, University of Amsterdam
- Amsterdam Brain and Cognition, University of Amsterdam
- Department of Artificial Intelligence and Cognitive Engineering, University of Groningen
- Department of Applied and Experimental Psychology, Vrije Universiteit Amsterdam
Abstract
The attentional blink (AB) phenomenon reveals a bottleneck of human information processing: the second of two targets is often missed when they are presented in rapid succession among distractors. In our previous work, we showed that the size of the AB can be changed by applying transcranial direct current stimulation (tDCS) over the left dorsolateral prefrontal cortex (lDLPFC) (Journal of Cognitive Neuroscience, 33, 756–68, 2021). Although AB size at the group level remained unchanged, the effects of anodal and cathodal tDCS were negatively correlated: if a given individual’s AB size decreased from baseline during anodal tDCS, their AB size would increase during cathodal tDCS, and vice versa. Here, we attempted to replicate this finding. We found no group effects of tDCS, like the original study, but we no longer found a significant negative correlation. We present a series of statistical measures of replication success, all of which confirm that both studies are not in agreement. First, the correlation here is significantly smaller than a conservative estimate of the original correlation. Second, the difference between the correlations is greater than expected due to sampling error, and our data are more consistent with a zero-effect than with the original estimate. Finally, the overall effect when combining both studies is small and not significant. Our findings thus indicate that the effects of lDPLFC-tDCS on the AB are less substantial than observed in our initial study. Although this should be quite a common scenario, null findings can be difficult to interpret and are still under-represented in the brain stimulation and cognitive neuroscience literatures. An important auxiliary goal of this paper is therefore to provide a tutorial for other researchers, to maximize the evidential value from null findings.
#Setup
library(knitr) # rmarkdown output
library(papaja) # APA formatted manuscripts
library(here) # (relative) file paths
library(ggm) # partial correlations
library(psychometric) # confidence intervals for (partial) correlations
library(pwr) # power analysis
library(TOSTER) # equivalence tests
library(predictionInterval) # prediction intervals
library(metafor) # meta-analysis
library(afex) # analysis of factorial experiments (repeated measures anova)
library(tidyverse) # importing, transforming, and visualizing data frames
library(cowplot) # themes and placement of graphs (installed from github)
library(kableExtra) # complex tables
# These are not used here, but in other notebooks, so load for referencing purposes
library(BayesFactor) # Bayesian statistics
library(broom) # transform model output into a data frame
library(emmeans) # post-hoc tests / contrasts
library(scales) # Percentage axis labels
knitr::opts_chunk$set(results='hide',
message=FALSE,
warning=FALSE)
# Code not in packages
source(here("src", "func", "behavioral_analysis.R")) # loading data and calculating measures
knitr::read_chunk(here("src", "func", "behavioral_analysis.R")) # display code from file in this
source(here("src", "lib", "appendixCodeFunctionsJeffreys.R")) # replication Bayes factors
# Online: source("https://osf.io/v7nux/download")
# Variables
base_font_size <- 9;
geom_text_size <- (base_font_size-1) * 0.35 # so geom_text size is same as axis text
base_font_family <- "Helvetica";# Seed for random number generation
set.seed(42)
knitr::opts_chunk$set(cache.extra = knitr::rand_seed)#library(osfr)
#osf_retrieve_node("rju7f") %>%
# osf_ls_files() %>%
# osf_download()
#zip.file.extract(file, zipname = "R.zip", unzip = getOption("unzip"))load_data_study2 <- function(dataDir, subs_incomplete) {
subID = list.dirs(dataDir, full.names = FALSE, recursive = FALSE) # get subject names
subID = subID[grep("S", subID)];
numSubjects <- length(subID);
# factors
#stimulation <- c("Y", "X") # "Y" codes for either anodal or cathodal; "X" codes for the opposite polarity
stimulation <- c("anodal", "cathodal") # "Y" codes for either anodal or cathodal; "X" codes for the opposite polarity
tDCScode_batch1 <- c("B", "D") # from S01 through S21, setting "B" corresponds "Y" and setting "D" corresponds to "X"
tDCScode_batch2 <- c("D", "I") # from S22 onwards, setting "D" corresponds "Y" and setting "I" corresponds to "X"
block <- c("pre", "tDCS", "post")
lag <- c(3,8)
# initialize group data frame
colHeader <- c("subject", "first.session", "stimulation", "block", "lag", "trials", "T1", "T2", "T2.given.T1") # name the variables (column header)
frameCols <- length(colHeader)
repRows <- length(stimulation)*length(block)*length(lag) # number of rows in data frame belonging to 1 subject
frameRows <- numSubjects*repRows
groupData <- data.frame(matrix(ncol=frameCols, nrow=frameRows)) # create group data frame with appropriate dimensions
names(groupData) <- colHeader #assign variable names to the data frame
# fill fixed variables
groupData$subject <- rep(subID, each = repRows)
groupData$stimulation <- factor(rep(stimulation, each = length(block)*length(lag), times = numSubjects))
groupData$block <- factor(rep(block, each = length(lag), times = numSubjects), levels = block)
groupData$lag <- factor(rep(lag, times = numSubjects))
for (iSub in subID) {
if (is.element(iSub, subs_incomplete)) { # if current subject should be excluded, skip to next one
next
}
if ( (as.numeric(substr(iSub,2,3))) <= 21) { # if subject was in first batch
tDCScode <- tDCScode_batch1 # these tDCS codes were used
} else {
tDCScode <- tDCScode_batch2
}
for (iStim in tDCScode) {
for (iBlock in block) {
# load file(s)
dataFiles = Sys.glob(file.path(dataDir, iSub, paste("AB_", iSub, "_*", iStim, "_", iBlock, "*.txt", sep = ""))) #file name
for (iFile in 1:length(dataFiles)) { # loop in the case of multiple files
if (iFile == 1) {
ABdata <- read.table(dataFiles[iFile], header = TRUE) #load single subject data
next
} else {
tempData <- read.table(dataFiles[iFile], header = TRUE) # load next file, if there is one
ABdata <- merge(ABdata, tempData, all = TRUE, sort = FALSE) # paste on to bottom of data frame
}
}
for (iLag in lag) { # for each lag
# extract single-subject measures
trialsLag <- ABdata$lag == iLag # indices of trials with this lag
numTrials <- sum(trialsLag) # number of trials of this lag
trialsT1 <- ABdata$T1acc == 1 # indices of T1 correct trials
T1 <- sum(trialsT1 & trialsLag) / numTrials # proportion of T1 correct trials
trialsT2 <- ABdata$T2acc == 1 # indices of T2 correct trials
T2 <- sum(trialsT2 & trialsLag) / numTrials # proportion of T1 correct trials
nonBlink <- sum(trialsLag & trialsT1 & trialsT2) / sum(trialsLag & trialsT1) # proportion of T2 given T1 correct trials
# insert into data frame
cellIdx = groupData$subject == iSub & groupData$stimulation == stimulation[tDCScode == iStim] & groupData$block == iBlock & groupData$lag == iLag # get index of current cell
# fill with data
groupData$trials[cellIdx] <- numTrials
groupData$T1[cellIdx] <- T1
groupData$T2[cellIdx] <- T2
groupData$T2.given.T1[cellIdx] <- nonBlink
}
}
if (grepl(paste("1", iStim, sep = ""), dataFiles[iFile])) { # if current file was the 1st session
groupData$first.session[groupData$subject == iSub] <- stimulation[tDCScode == iStim] # store the stimulation type
}
}
}
groupData$first.session <- factor(groupData$first.session)
return(groupData)
}# these participants have incomplete data and should be excluded
subs_incomplete <- c("S03", "S14", "S25", "S29", "S31", "S38", "S43", "S46")
df_study2 <- load_data_study2(here("data"), subs_incomplete) %>%
filter(complete.cases(.)) %>% # discard rows with data from incomplete subjects
# recode first.session ("anodal" or "cathodal") to session.order ("anodal first", "cathodal first")
mutate(first.session = parse_factor(paste(first.session, "first"),
levels = c("anodal first", "cathodal first"))) %>%
rename(session.order = first.session)1 Introduction
The attentional blink (AB) phenomenon clearly demonstrates that our capacity to process incoming information is easily overwhelmed. The AB occurs when two targets are embedded in a rapidly presented stream of distractors (Raymond, Shapiro, and Arnell 1992; for reviews, see Paul E. Dux and Marois 2009; Martens and Wyble 2010). The first target (T1) is usually reported with little difficulty. When there is a longer lag between the two targets [> 500 ms; MacLean and Arnell (2012)], accuracy for the second target (T2) can be on par with the first. However, for shorter lags, T2 is most often missed—as if the attentional system momentarily faltered (“blinked”).
While the AB might seem to be a fundamental bottleneck, it can under some circumstances be overcome. For example, the size of the AB can be reduced by distracting activities (Christian N. L. Olivers et al. 2005; Christian N. L. Olivers and Nieuwenhuis 2006; Thomson et al. 2015), or after following an intensive mental training program (Heleen A. Slagter et al. 2007). Others have tried to use non-invasive brain stimulation (Dayan et al. 2013) as a means to influence the AB. Several studies have shown that repetitive transcranial magnetic stimulation (TMS) can improve target perception in AB tasks (Cooper et al. 2004; Arasanz, Staines, and Schweizer 2012; Esterman et al. 2017). Yet, as TMS did not show a differential effect for targets presented at shorter or longer lags, it did not affect the AB itself.
Transcranial direct current stimulation (tDCS) is another brain stimulation technique that has gained traction in the past two decades. In tDCS, an electrical current flows between an anodal and cathodal electrode, which can affect the excitability of the underlying cortex (Gebodh et al. 2019). Anodal stimulation generally enhances cortical excitability, while cathodal stimulation may have an inhibitory effect (Nitsche and Paulus 2000; Nitsche and Paulus 2001) (though note that this does not hold in all cases (Parkin et al. 2018), and the underlying physiology is complex (Bikson et al. 2019; Liu et al. 2018; Stagg, Antal, and Nitsche 2018)).
A previous study by our group (London and Slagter 2021) recently examined the effects of tDCS on the AB. In this study, anodal and cathodal tDCS were applied over the left dorsolateral prefontal cortex (lDPLFC, with the other electrode on the right forehead)—one of the core brain areas implicated in the AB (Heleen A. Slagter et al. 2010; Hommel et al. 2006). At the group level, tDCS did not appear to have any effects on AB size. However, anodal and cathodal tDCS did appear to systematically affect the AB within individuals, as their effects were negatively correlated. For a given individual, this negative correlation implies that when AB size decreased (compared to a baseline measurement) during anodal tDCS, AB size would increase during cathodal tDCS (or vice versa).
Our previous (2021) findings complement earlier literature showing large individual differences in both the AB (Willems and Martens 2016) and effects of tDCS (Krause and Cohen Kadosh 2014). However, only one other tDCS study of the AB exists to date, which in fact did find a group-level effect of stimulation, in contrast to London and Slagter (2021) (Sdoia et al. (2019)). Also, the negative correlation between the effects of anodal and cathodal tDCS has so far only been reported in London and Slagter (2021), and was based on an exploratory analysis. We thus decided to conduct another study aiming to replicate this finding. Replication of findings in general is important to establish credibility of scientific claims (Schmidt 2016), and in this specific case, reproduction of our original findings would be informative about the ability of tDCS to modulate the apparent bottleneck in information processing captured by the AB, and about the importance of left dorsolateral prefrontal cortex in the AB and attentional filtering more generally. Thus, we aimed to confirm our previous results and conclusions.
To foreshadow our results, like London and Slagter (2021), we did not find a group effect of tDCS on the AB. However, the correlation between the effects of anodal and cathodal tDCS was also not significant. Although this indicates that the two studies may differ, a failure to reject the null hypothesis by itself does not tell us much (Harms and Lakens 2018): it is crucial to also take measures of the uncertainty and effect size in both studies into account (Simonsohn 2015). That said, there is no consensus on when a replication can be considered successful or not (Brandt et al. 2014), let alone a single statistical test to definitely answer this question conclusively (Anderson and Maxwell 2016).
Therefore, we employ a number of statistical methods to maximize the evidential value in these two studies. We ask three questions (cf. Zondervan-Zwijnenburg and Rijshouwer (2020)) that all aim to evaluate to what extent the present study is a successful replication (Zwaan et al. 2018; cf. Camerer et al. 2018; Open Science Collaboration 2015) of our previous work (London and Slagter 2021). First, while the effect in our study was not significant, there might still be a meaningful effect that is simply smaller than anticipated. Therefore, we used equivalence testing (Daniël Lakens, Scheel, and Isager 2018) to answer the question “is the correlation in study 2 significantly small?” Second, although our current result differs from London and Slagter (2021), it could still be more consistent with our previous findings than with alternative explanations. So in addition, we asked “is the correlation in study 2 different from study 1?” and aimed to answer this question using prediction intervals (Spence and Stanley 2016; Patil, Peng, and Leek 2016) and replication Bayes factors (Eric-Jan Wagenmakers, Verhagen, and Ly 2016; Verhagen and Wagenmakers 2014). Finally, it could be that the effect in our study alone is not sufficiently large, but the overall effect based on both studies is. This raises the question “is the effect significant when combining study 1 and 2?” which we addressed through meta-analysis (Quintana 2015; Goh, Hall, and Rosenthal 2016) and by pooling the data.
These questions address issues of reproducibility that are currently faced by many in the brain stimulation field (Héroux et al. 2017), and in the cognitive neuroscience community at large (Munafò et al. 2017; Huber, Potter, and Huszar 2019). Therefore, aside from our focus on tDCS and the AB, an important auxiliary goal of this article is to provide a tutorial on the statistical evaluation of replication studies (also see Daniël Lakens et al. (2020), Zondervan-Zwijnenburg and Rijshouwer (2020)). We hope this may prove useful to other researchers who find themselves in similar situations.1
2 Methods
2.1 Participants
subject_info <- read_csv2(here("data", "subject_info.csv"), progress = FALSE,
col_names = TRUE,
col_types = cols(
first.session = readr::col_factor(c("anodal", "cathodal")),
gender = readr::col_factor(c("male", "female")),
age = col_integer())) %>%
filter(!(subject %in% c(subs_incomplete, "S42"))) %>%
# recode first.session ("anodal" or "cathodal") to session.order ("anodal first", "cathodal first")
mutate(first.session = parse_factor(paste(first.session, "first"),
levels = c("anodal first", "cathodal first"))) %>%
rename(session.order = first.session)n_study2 <- n_distinct(subject_info$subject)
n_female <- sum(subject_info$gender == "female")
age_mean <- mean(subject_info$age, na.rm = TRUE)
age_sd <- sqrt(sum((subject_info$age - age_mean)^2,
na.rm=TRUE)/sum(!is.na(subject_info$age))) # population SD
age_min <- min(subject_info$age, na.rm = TRUE)
age_max <- max(subject_info$age, na.rm = TRUE)Fourty-eight participants took part in total, eight of whom were excluded after the first session. One participant was excluded as a precaution because they developed an atypical headache after the first session, and we could not rule out this was related to the tDCS. Another stopped responding to our requests to schedule the second session. Another six participants were excluded because their mean T1 accuracy in the first session was too low, which implies they were not engaged in the task in the manner we expected, and would leave fewer trials to analyze, because our T2 accuracy measure included only trials in which T1 was seen. We used a cut-off of 63% T1 accuracy as an exclusion criterium, which was two standard deviations below the mean of a separate pilot study (n = 10).
This left a final sample of 40 participants (29 female, mean age = 20.94, SD = 2.45, range = 18–28). This sample size was determined a priori to slightly exceed London and Slagter (2021) (n = 34).
The experiment and recruitment took place at the University of Amsterdam. All procedures for this study were approved by the ethics review board of the Faculty for Social and Behavioral Sciences, and complied with relevant laws and institutional guidelines. All participants provided their written informed consent and were compensated with course credit or €10 per hour (typically €65 for completing two full sessions).
2.2 Procedure
The study procedures were identical to London and Slagter (2021): participants received anodal and cathodal tDCS in separate sessions (Figure 2.1), which typically took place exactly one week apart (cf. minimum of 48 hours in London and Slagter (2021)). The time in between served to keep the sessions as similar as possible, and to minimize the risk of tDCS carry-over effects. 18 participants received anodal tDCS in the first session and cathodal tDCS in the second, and vice versa for the remaining 22 participants.
knitr::include_graphics("figures/figure_1_procedure.png", auto_pdf = TRUE)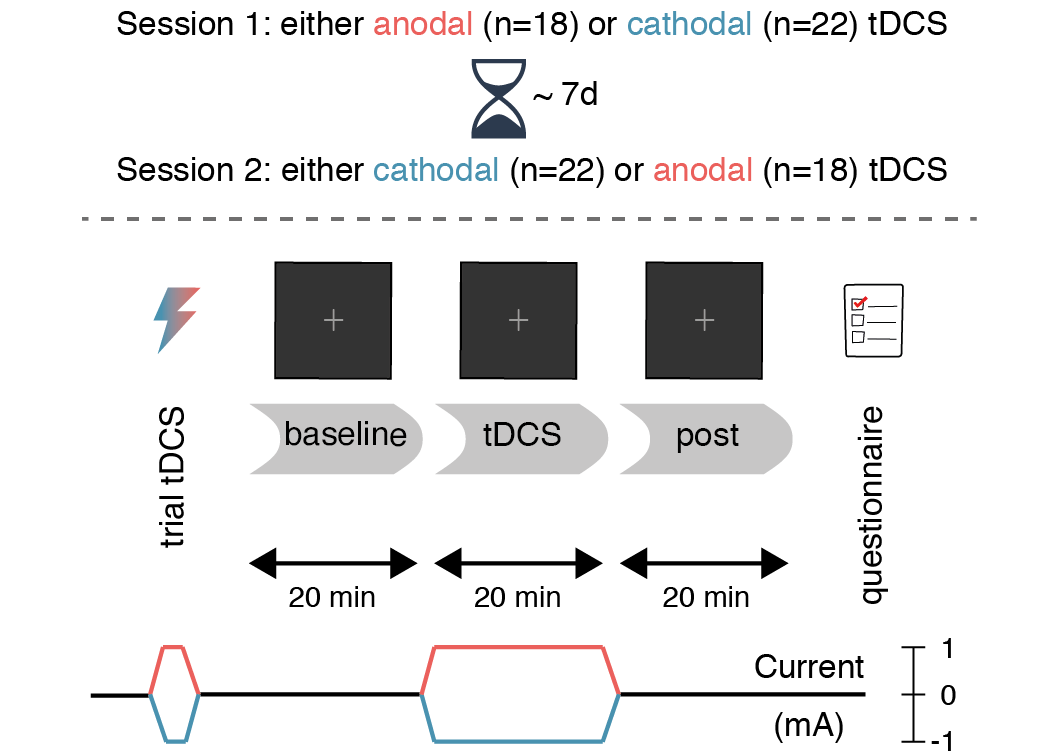
Figure 2.1: Experimental design. After a baseline block without stimulation, participants performed the attentional blink task during 20 minutes of anodal (red) or cathodal (blue) tDCS, followed by a post-test block (also without stimulation). The second session (typically 7 days later) was identical, except that the tDCS polarity was reversed.
First, participants experienced the sensations induced by tDCS in a brief trial stimulation (see the tDCS section). Next, participants completed 20 practice trials of the task (see the Task section). For the main portion of the experiment, participants performed three blocks of the task (Figure 2.1): before tDCS (baseline), during anodal/cathodal tDCS (tDCS), and after tDCS (post). Finally, after completing the three blocks, participants filled in a questionnaire on tDCS-related adverse effects (see Table 4.1 and Figure 4.1 in the Supplementary Material).
Within each block of the task, participants took a self-timed break every 50 trials (~5 minutes); between the blocks, the experimenter walked in. Participants performed the task for exactly 20 minutes during the baseline and post blocks. During the tDCS block, the task started after the 1-minute ramp-up of the current was complete, and continued for 21 minutes (constant current, plus 1-minute of ramp-down).
2.3 Task
The attentional blink task (Figure 2.2) was almost identical to the one we used previously (London and Slagter 2021; Heleen A. Slagter and Georgopoulou 2013) (see Table 4.2 for a full list of the differences), which in turn was based on an earlier task by Paul E. Dux and Marois (2008). A rapid serial visual presentation stream of 15 letters was shown on each trial, using Presentation software (Neurobehavioral Systems, Inc.). Each letter was displayed for 91.7 ms (11 frames at 120 Hz) on a dark gray background. The letters were presented in font size 40 (font: Courier New) at a viewing distance of 90 cm. On each trial, the letters were randomly sampled without replacement from the alphabet, excluding the letters I, L, O, Q, U and V, as they were too similar to each other. All distractor letters were mid-gray, whereas T1 and T2 were colored. T1 was red and always appeared at position 5 in the stream. T2 was green and followed T1 after either 2 distractors (lag 3) or 7 distractors (lag 8) (cf. lags 2, 4 and 10 in London and Slagter (2021)).
The letter stream was preceded by a fixation cross (same color as the letters) presented for 1750 ms and followed by another fixation cross. Finally, the participant was prompted to type in (using a standard keyboard) the letter they thought was presented as T1 (“Which letter was red?”), followed by T2 (“Which letter was green?”).
trials_study2 <- df_study2 %>%
group_by(lag) %>%
summarise_at(vars(trials), funs(mean, min, max, sd))Trial duration varied slightly because both the T1 and T2 response questions were self-paced, so some participants completed more trials than others depending on their response times. On average, participants completed 130 short lag trials (SD = 17; range = 78–163) and 65 long lag trials (SD = 9; range = 39–87) per 20-minute block.
knitr::include_graphics("figures/figure_2_task.png", auto_pdf = TRUE)
Figure 2.2: Attentional blink task. Participants viewed rapid serial visual presentation streams of 15 letters, all of which were distractors (gray letters) except for T1 and T2. T1 was presented in red at position 5; T2 was presented in green and followed T1 after 2 distractors (lag 3, inside the AB window) or 7 distractors (lag 8, outside the AB window). At the end of the trial, participants reported the identity of T1 and then T2 (self-paced).
#,
#out.width = "\\textwidth", fig.pos = "!h"2.4 tDCS
Transcranial direct current stimulation was delivered online (i.e. during performance of the attentional blink task) using a DC-STIMULATOR PLUS (NeuroCare Group GmbH). The current was ramped up to 1 mA in 1 minute, stayed at 1 mA for 20 minutes, and was ramped down again in 1 minute.
One electrode was placed at F3 (international 10-20 system) to target the lDLPFC; the other was placed over the right forehead, centered above the eye (approximately corresponding to position Fp2). Both electrodes were 5 x 7 cm in size (35 cm2), leading to a current density of 0.029 mA/cm2. The montage and tDCS parameters are identical to London and Slagter (2021), the only exception being the conductive medium. We used Ten20 conductive paste (Weaver and Company), because it was easier to apply concurrently with the EEG equipment (see the EEG section); London and Slagter (2021) used saline solution as a conductive medium, together with rubber straps to keep the electrodes in place.
Participants received either anodal tDCS (anode on F3, cathode on right forehead) or cathodal tDCS (cathode on F3, anode on right forehead) in separate sessions. The procedure was double-blinded: both the participant and the experimenters were unaware which polarity was applied in a given session. The experimenter loaded a stimulation setting on the tDCS device (programmed by someone not involved in data collection), without knowing whether it was mapped to anodal or cathodal tDCS. In the second session, the experimenter loaded a second setting mapped to the opposite polarity (half the dataset), or simply connected the terminals of the device to the electrodes in the opposite way.
At the start of the experiment, participants received a brief trial stimulation, based on which they decided whether or not they wanted to continue with the rest of the session. The experimenter offered to terminate the experiment in case tDCS was experienced as too uncomfortable, but none of the participants opted to do so. For the trial stimulation, the current was ramped up to 1 mA in 45 seconds, stayed at 1 mA for 15 seconds, and was ramped down again in 45 seconds.
2.5 EEG
We also recorded EEG during all three task blocks. As noted in the Introduction, we refrained from further analysis of the EEG data, given the absence of a behavioral effect. Instead, we are making the EEG data publicly available at this time.2 The dataset is formatted according to the Brain Imaging Data Structure (BIDS) standard (Gorgolewski et al. 2016) for EEG (Pernet et al. 2019), to facilitate re-use. We include the raw data, as well as the fully preprocessed data and the MATLAB code that generated it.
2.6 Data analysis
r_citations <- cite_r(file = "r-references.bib",
pkgs = c("broom","cowplot","here","tidyverse","papaja","knitr",
"psychometric","pwr","kableExtra","BayesFactor","emmeans"),
withhold = FALSE,
footnote = TRUE)Data were analyzed using R [Version 3.6.2; R Core Team (2019)]3 from within RStudio [Version 1.1.463; RStudio Team (2016)].
2.6.1 Group-level analysis
Repeated measures ANOVAs were conducted on T1 accuracy (percentage of trials where T1 was reported correctly) and T2|T1 accuracy (percentage of trials where T2 was reported correctly, out of the subset of T1-correct trials) using the afex package [Version 0.28-1; Singmann et al. (2021)]. The same factors were included for both repeated measures ANOVAs, following London and Slagter (2021): Lag (3, 8), Block (baseline, tDCS, post), Stimulation (anodal, cathodal), and the between-subject factor Session order (anodal tDCS in the first session vs. cathodal tDCS in the first session). Effect sizes are reported as generalized eta-squared (\(\hat{\eta}^2_G\)) (Bakeman 2005). Greenhouse-Geisser-adjusted degrees of freedom (\(\mathit{df}^{GG}\)) and p-values are reported as a correction for sphericity violations.
2.6.2 Individual differences analysis
We reproduced the analysis behind Figure 4 of London and Slagter (2021), which showed a differential effect of anodal vs. cathodal tDCS at the individual participant level. First, we calculated AB magnitude by subtracting T2|T1 accuracy at lag 3 from T2|T1 accuracy at lag 8. Next, change scores were created by subtracting AB magnitude in the baseline block from the tDCS and the post blocks, respectively. The change scores in the anodal and cathodal session were then correlated to each other. Again following London and Slagter (2021), we computed a partial correlation (using the ggm package [Version 2.5; Marchetti, Drton, and Sadeghi (2020)]), attempting to adjust for variance due to Session order.
2.6.3 Replication analyses
In contrast to London and Slagter (2021), the analysis described in the previous section did not produce a significant correlation in our dataset. Therefore, we conducted five follow-up analyses that aim to quantify to what extent our results (do not) replicate London and Slagter (2021). These all provide a complementary perspective on this question. First, we performed an equivalence test (1) to assess whether the effect in the present study was significantly smaller than in London and Slagter (2021). While this procedure is more focused on hypothesis testing, we also constructed prediction intervals (2) to capture the range of effect sizes we can expect in a replication of London and Slagter (2021). Both of these procedures are based on frequentist statistics, which cannot directly quantify the amount of evidence for a (null) hypothesis. Therefore, we also computed a replication Bayes factor that expresses whether the data in the present study are more likely under the null hypothesis that the effect is absent, vs. the alternative hypothesis that the effect is comparable to London and Slagter (2021). Finally, we directly combined both studies and estimated the size of the overall effect, through meta-analysis (4) of both correlations, and by computing a new correlation on the pooled dataset (5). More details on each analysis can be found in the following sections, and the provided online resources (see the Data, materials, and code availability section).
2.6.3.1 Equivalence tests
Equivalence tests can be used to test for the absence of an effect of a specific size (see Daniël Lakens, Scheel, and Isager 2018 for a tutorial). Usually, the effect size used for the test is the smallest effect size of interest (the SESOI). Typically, equivalence tests are two one-sided tests: one test of the null hypothesis that the effect exceeds the upper equivalence bound (positive SESOI), and one that the effect exceeds the lower equivalence bound (negative SESOI). However, a one-sided test is more appropriate here: London and Slagter (2021) found that the effects of anodal and cathodal tDCS were anticorrelated, so we are only interested in negative effect sizes. This is known as an inferiority test (Daniël Lakens, Scheel, and Isager 2018).
We follow the “small telescopes” (Simonsohn 2015) approach to set the SESOI to \(r_{33\%}\): the correlation that London and Slagter (2021) had 33% power to detect. The reasoning behind this approach is that it is difficult to prove that an effect does not exist at all, but easier to show that it is surprisingly small. An equivalence test can suggest that the effect is unlikely to exceed \(r_{33\%}\), such that the odds to detect it were stacked at least 2:1 against London and Slagter (2021). That would not mean the effect does not exist at all, but it would mean the original evidence for the effect is not very convincing, as “too small a telescope” (in this case, an inadequate sample size) was used to reliably detect it.
There are many possible specifications of the SESOI, none of which are necessarily wrong or right (Daniël Lakens, Scheel, and Isager 2018). We favored the “small telescopes” approach because it constitutes a relatively strict test—\(r_{33\%}\) is much smaller than the original correlation in London and Slagter (2021). Because the observed correlation in London and Slagter (2021) could have overestimated the true correlation, it is prudent to set the SESOI to be smaller. Furthermore, the approach was specifically designed to evaluate replication results (Simonsohn 2015), and has been used previously in large-scale replication studies (e.g. Camerer et al. 2018). However, recent simulation studies have also demonstrated that equivalence tests for replications can be either too liberal (especially in the case of publication bias) (Muradchanian et al. 2020), or too conservative (especially in case of low sample sizes) (Linde et al. 2020).
We conducted an inferiority test using the TOSTER package [Version 0.3.4; Daniel Lakens (2017)] against the null hypothesis that the correlation coefficient in the present study is at least as negative as \(-r_{33\%}\). At a standard alpha level of 0.05, the test is significant if the 90% confidence interval around the observed correlation does not contain \(r_{33\%}\). This would mean that the observed correlation should be considered “statistically inferior,” as it is then significantly smaller (i.e. less negative) than \(-r_{33\%}\).
2.6.3.2 Prediction interval
Prediction intervals contain a range of values we can expect a new observation to fall within. In our case, the observation of interest is the correlation between the effects of anodal and cathodal tDCS. This correlation is estimated based on a sample, and is thus subject to sampling error: any two estimates of the correlation will almost never be exactly the same. Prediction intervals aim to quantify how dissimilar two estimates can be before we should be surprised.
Here, we construct a prediction interval around the original estimate of the correlation in London and Slagter (2021). This prediction interval contains the range of correlation coefficients we can expect to see in the present study, given the results of London and Slagter (2021). The width of the interval depends on the sample sizes of both studies, as larger samples will reduce variation in the estimates, leading to smaller prediction intervals (Patil, Peng, and Leek 2016).
If the original study were replicated 100 times, 95 of the observed correlation coefficients would fall within the 95% prediction interval (Patil, Peng, and Leek 2016). Note that this definition is related to, but different from, a confidence interval, which quantifies uncertainty about the (unknown) true correlation in the population (95 out of every hundred constructed 95% confidence intervals contain the true population parameter). Because prediction intervals concern the next single observation, they make a more specific claim, and will be wider than confidence intervals.
We calculated a 95% prediction interval for correlations, following Spence and Stanley (2016), using the predictionInterval package [Version 1.0.0; Stanley (2016)].
2.6.3.3 Replication Bayes factor
Bayes factors can be used to express the relative evidence for the null (\(H_0\)) or alternative hypothesis (\(H_1\)) (Eric Jan Wagenmakers, Marsman, et al. 2018). In a default Bayesian hypothesis test, \(H_0\) states the effect size is absent (i.e. exactly zero); \(H_1\) states that the effect is present (specified further by a prior distribution of effect sizes).
In a replication context, we want to decide between two different scenarios (Verhagen and Wagenmakers 2014). \(H_0\) is the hypothesis of an idealized skeptic, who disregards the information from the original study and believes the effect is absent. The alternative hypothesis \(H_r\) belongs to an idealized proponent, who believes that the effect is exactly as in the original study, i.e. their prior distribution is simply the posterior distribution of the original study.
We used the replication Bayes factor test for correlations developed by Eric-Jan Wagenmakers, Verhagen, and Ly (2016). The replication Bayes factor \(BF_{0r}\) expresses evidence for \(H_0\) : “the correlation is 0” relative to \(H_r\) : “the correlation is as in the original study.” We use the interpretation scheme from Eric Jan Wagenmakers, Love, et al. (2018), where \(1 < BF_{0r} < 3\) consitutes “anecdotal evidence” for \(H_0\), \(3 < BF_{0r} < 10\) ~ “moderate evidence,” and \(10 < BF_{0r} < 30\) ~ “strong evidence.”
2.6.3.4 Meta-analysis
The outcomes from multiple studies on the same phenomenon can be combined through meta-analysis. Here we compute a meta-analytic estimate of the correlation based on the correlations observed here and as reported by London and Slagter (2021), using the metafor package [Version 2.4-0; Viechtbauer (2010)]. We weighed the estimate by sample size, as larger studies allow for more precise effect size estimates, and thus should also contribute more to the overall meta-analytic estimate. In our case, this means the present study will have a slightly higher influence on the meta-analytic effect size (because its sample size exceeds London and Slagter (2021)). We specified the meta-analysis as a fixed-effects model, because both studies are highly similar and from the same population (e.g., the experiments were conducted in the same location, and the sample was from the same university student population). With a fixed-effects analysis, we estimate the size of the effect in the set of available studies, meaning our inferences cannot generalize beyond. A random-effects meta-analysis would be appropriate in case the studies were more dissimilar, and if we sought an estimate of the true effect in the population, but we would need more than just two studies for this approach. When more studies are available, and it is not immediately clear whether fixed- or random-effects meta-analysis is more appropriate, it is advisable to report both (Goh, Hall, and Rosenthal 2016). Note that while meta-analyses are a powerful way to assess the overall effect in a series of studies, they are particularly vulnerable to false positives when there is publication bias (Muradchanian et al. 2020), or if the selection of studies (or any single study) is biased (Ueno, Fastrich, and Murayama 2016).
2.6.3.5 Pooling the data with London and Slagter (2021)
Another approach is to pool the single-subject data from both studies, and to re-calculate the partial correlation on the combined sample (n = 74). The main difference between the two studies is that London and Slagter (2021) presented T2 at lags 2, 4 and 10; here we used lags 3 and 8. The long lags (lag 8 vs. lag 10) should be fairly comparable, as they are both well outside the attentional blink window [> 500 ms following T1; MacLean and Arnell (2012)]. However, there should be a sizeable performance difference at the short lags (lag 2 vs. lag 3), as the attentional blink is larger at lag 2 than lag 3. Therefore, we opted to also create a “lag 3” condition in the data from London and Slagter (2021), by averaging T2|T1 accuracy at lag 2 and lag 4. The difference from lag 2 to 4 (and 4 to 10) in London and Slagter (2021) looks fairly linear (see their Figure 3), so this seems a fair approximation of “true” lag 3 performance. Afterwards we recomputed the partial correlation between AB magnitude change scores as described previously (see the Individual differences analysis section).
Note that this analysis is tailored to this series of studies, and not generally advisable. To get a more accurate estimate of the effect at lag 3, it is necessary to redo the analysis on the larger, combined sample. But repeating a statistical test after collecting more data (“optional stopping”) invalidates the interpretation of the p-value and can drastically increase the false positive rate (Simmons, Nelson, and Simonsohn 2011). This would only be acceptable when the analysis plan has been preregistered, and the false positive rate of sequential analyses is controlled (for potential solutions, see Daniël Lakens 2014). We therefore do not report a p-value for this test, but only the effect size and its confidence interval.
2.7 Data, materials, and code availability
All of the data and materials from this study and the data from London and Slagter (2021) are available on the Open Science Framework4. The analysis code is available on GitHub5 (and also from our OSF page), in the form of an R notebook detailing all the analyses that we ran for this project, along with the results. We also include an Rmarkdown (Xie, Allaire, and Grolemund 2018) source file for this paper that can be run to reproduce the pdf version of the text, along with all the figures and statistics.
3 Results
3.1 Group-level analysis
df_plot_T2 <- df_study2 %>%
group_by(lag,stimulation,block) %>%
summarise(Mean = mean(T2.given.T1)) %>% # calculate mean per facto
# add within-subject confidence intervals
inner_join(wsci(data = df_study2, id = "subject",
factors = c("stimulation", "block", "lag"), dv = "T2.given.T1")) %>%
rename(CI = T2.given.T1) %>%
add_column(measure = "T2|T1")
df_plot_T1 <- df_study2 %>%
group_by(lag,stimulation,block) %>%
summarise(Mean = mean(T1)) %>% # calculate mean per facto
# add within-subject confidence intervals
inner_join(wsci(data = df_study2, id = "subject",
factors = c("stimulation", "block", "lag"), dv = "T1")) %>%
rename(CI = T1) %>%
add_column(measure = "T1")aov_T2.given.T1 <- aov_car(T2.given.T1 ~ session.order + Error(subject/(block*stimulation*lag)),
data = df_study2)
apa_aov_T2.given.T1 <- apa_print(aov_T2.given.T1, mse = FALSE, in_paren = TRUE)T2_desc <- function(df, block_in) {
df %>%
filter(block == block_in) %>%
mutate(cond = paste0("lag ", lag, "_", block_in)) %>%
unite(ID, stimulation, session.order) %>%
group_by(ID, cond) %>%
summarise(mean_sd = paste0(printnum(mean(T2.given.T1), digits = 3), " (",
printnum(sd(T2.given.T1), digits = 3), ")")) %>%
spread(ID, mean_sd) %>%
select(cond, contains("anodal first"), contains("cathodal first"))
}Figure 3.1 shows the attentional blink (T2|T1 accuracy per lag) for each of the three blocks (pre, tDCS, post) and stimulation conditions separately. The summary statistics and ANOVA results for T2|T1 accuracy can be found in Tables 3.1 and 3.2. There was a clear attentional blink effect on average (main effect of Lag, \(F[1, 38] = 432.11\), \(p < .001\)), as T2|T1 accuracy for lag 8 was higher than lag 3.
ggplot(full_join(df_plot_T1,df_plot_T2),
aes(lag, Mean, color = stimulation, shape = stimulation, linetype = measure)) +
facet_wrap(~block) +
geom_line(aes(group = interaction(measure, stimulation)),
size = .75, position = position_dodge(width = 0.5)) +
geom_linerange(aes(group = interaction(measure, stimulation),
ymin = Mean-CI, ymax = Mean+CI),
position = position_dodge(width = 0.5), show.legend = FALSE) +
geom_point(aes(group = interaction(measure, stimulation)),
size = 2, position = position_dodge(width = 0.5)) +
scale_y_continuous("Accuracy", limits = c(0,1), breaks = seq(0,1,.1),
labels = scales::percent_format(accuracy=10), expand = c(0,0)) +
scale_color_manual(values = c("#F25F5C", "#4B93B1")) +
theme_minimal_hgrid(font_size = base_font_size, font_family = base_font_family) +
theme(strip.background = element_rect(fill = "grey90"),
axis.ticks.x = element_line(),axis.ticks.y = element_blank(), axis.ticks.length = unit(.5,"lines"),
legend.title = element_blank())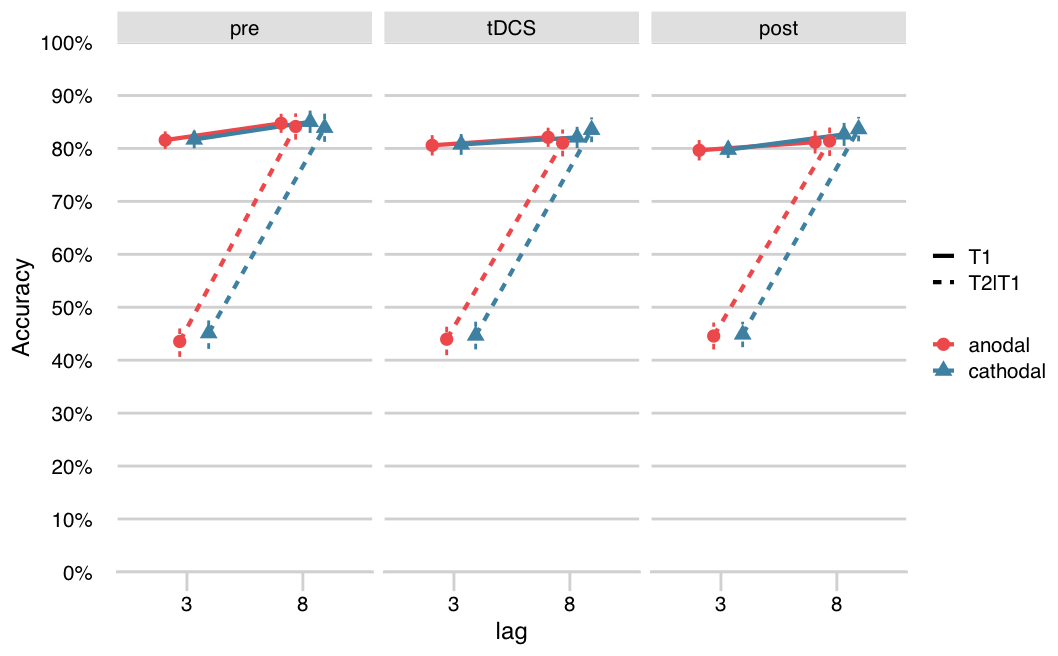
Figure 3.1: No effects of tDCS on the attentional blink at the group level. There was a clear attentional blink effect: a lower % T2 accuracy (given T1 correct: T2|T1; dashed lines) for lag 3 (T2 presented inside the attentional blink window) than lag 8 (T2 presented outside the attentional blink window, on par with T1 accuracy). However, the attentional blink did not change systematically over stimulation conditions (anodal, cathodal) and blocks (pre, tDCS, post). T1 accuracy (solid lines) was also not affected by tDCS.
# Table with kableExtra (html and pdf)
# bind tables for each "block" in a list
T2_df <- map_df(list("pre","tDCS","post"), T2_desc, df = df_study2)
T2_df <- mutate(T2_df, cond = str_remove(cond, "_.*")) # remove block info (gonna add below)
colnames(T2_df) <- str_remove(colnames(T2_df), "_.*") # remove session info (gonna add below)
T2_df %>%
kable(col.names = c("", colnames(T2_df)[2:5]), # drop first column name
caption = "Descriptive statistics for T2|T1 accuracy",
booktabs = TRUE) %>%
kable_styling() %>%
add_header_above(c(" " = 1, "First session: anodal (n = 18)" = 2, "First session: cathodal (n = 22)" = 2)) %>%
pack_rows(index = c("baseline" = 2, "tDCS" = 2, "post" = 2)) %>%
footnote(general = 'Values are "Mean (SD)"')| anodal | cathodal | anodal | cathodal | |
|---|---|---|---|---|
| baseline | ||||
| lag 3 | 0.395 (0.149) | 0.486 (0.167) | 0.469 (0.211) | 0.423 (0.168) |
| lag 8 | 0.826 (0.119) | 0.819 (0.095) | 0.854 (0.125) | 0.855 (0.087) |
| tDCS | ||||
| lag 3 | 0.415 (0.168) | 0.450 (0.165) | 0.460 (0.201) | 0.444 (0.188) |
| lag 8 | 0.787 (0.131) | 0.819 (0.098) | 0.830 (0.115) | 0.849 (0.096) |
| post | ||||
| lag 3 | 0.437 (0.171) | 0.451 (0.160) | 0.453 (0.190) | 0.447 (0.164) |
| lag 8 | 0.783 (0.118) | 0.825 (0.098) | 0.840 (0.145) | 0.846 (0.120) |
| Note: | ||||
| Values are “Mean (SD)” | ||||
Effects of tDCS at the group-level should manifest as a three-way interaction between Block, Stimulation, and Lag. As in London and Slagter (2021), this interaction was not significant (\(F[1.77, 67.17] = 2.77\), \(p = .076\)). However, the higher-order interaction with Session order did reach significance (\(F[1.77, 67.17] = 7.25\), \(p = .002\)). This interaction appears to be mostly driven by a learning effect across sessions and blocks (the Session order by Stimulation by Lag interaction). From the first to the second session, lag 3 performance improved, while lag 8 performance declined somewhat (leading to a smaller attentional blink). This change was stronger in participants that received anodal tDCS in the first session, and less pronounced in the cathodal-first group. We do not consider this a genuine effect of tDCS on the attentional blink, because there is no clear reason why these randomized groups should differ, and because the largest difference between the anodal and cathodal session occurred in the baseline block already (see Table 3.1).
apa_table(apa_aov_T2.given.T1$table, caption = "Repeated measures ANOVA on T2|T1 accuracy")| Effect | \(F\) | \(\mathit{df}_1^{GG}\) | \(\mathit{df}_2^{GG}\) | \(p\) | \(\hat{\eta}^2_G\) |
|---|---|---|---|---|---|
| Session order | 0.33 | 1 | 38 | .568 | .006 |
| Block | 1.13 | 1.91 | 72.71 | .328 | .001 |
| Stimulation | 2.47 | 1 | 38 | .125 | .002 |
| Lag | 432.11 | 1 | 38 | < .001 | .634 |
| Session order \(\times\) Block | 0.29 | 1.91 | 72.71 | .741 | .000 |
| Session order \(\times\) Stimulation | 5.55 | 1 | 38 | .024 | .005 |
| Session order \(\times\) Lag | 0.48 | 1 | 38 | .494 | .002 |
| Block \(\times\) Stimulation | 0.28 | 1.91 | 72.51 | .747 | .000 |
| Block \(\times\) Lag | 1.67 | 1.70 | 64.73 | .199 | .001 |
| Stimulation \(\times\) Lag | 0.10 | 1 | 38 | .751 | .000 |
| Session order \(\times\) Block \(\times\) Stimulation | 1.93 | 1.91 | 72.51 | .154 | .001 |
| Session order \(\times\) Block \(\times\) Lag | 0.24 | 1.70 | 64.73 | .752 | .000 |
| Session order \(\times\) Stimulation \(\times\) Lag | 5.84 | 1 | 38 | .021 | .002 |
| Block \(\times\) Stimulation \(\times\) Lag | 2.77 | 1.77 | 67.17 | .076 | .001 |
| Session order \(\times\) Block \(\times\) Stimulation \(\times\) Lag | 7.25 | 1.77 | 67.17 | .002 | .003 |
mean_T1 <- mean(df_study2$T1)
aov_T1 <- aov_car(T1 ~ session.order + Error(subject/(block*stimulation*lag)),
data = df_study2)
apa_aov_T1 <- apa_print(aov_T1, mse = FALSE, in_paren = TRUE)We ran the same repeated measures ANOVA for T1 accuracy (Table 3.3). On average, participants correctly identified T1 in 82% of trials (Figure 3.1), which is comparable to previous studies using this task (86% in London and Slagter 2021; 82% in Heleen A. Slagter and Georgopoulou 2013). T1 accuracy was also slightly lower for lag 3 than lag 8 (main effect of Lag, \(F[1, 38] = 29.23\), \(p < .001\)). There was a main effect of Block, reflecting that T1 accuracy decreased within a session (\(F[1.89, 71.87] = 6.64\), \(p = .003\)). Finally, T1 performance also decreased across the sessions (interaction between Session order and Stimulation: \(F[1, 38] = 11.24\), \(p = .002\)).
In sum, we conclude that there is no significant effect of tDCS on the attentional blink or T1 accuracy at the group level, in agreement with London and Slagter (2021).
apa_table(apa_aov_T1$table, caption = "Repeated measures ANOVA on T1 accuracy")| Effect | \(F\) | \(\mathit{df}_1^{GG}\) | \(\mathit{df}_2^{GG}\) | \(p\) | \(\hat{\eta}^2_G\) |
|---|---|---|---|---|---|
| Session order | 0.96 | 1 | 38 | .332 | .018 |
| Block | 6.64 | 1.89 | 71.87 | .003 | .010 |
| Stimulation | 0.00 | 1 | 38 | .996 | .000 |
| Lag | 29.23 | 1 | 38 | < .001 | .013 |
| Session order \(\times\) Block | 0.60 | 1.89 | 71.87 | .540 | .001 |
| Session order \(\times\) Stimulation | 11.24 | 1 | 38 | .002 | .030 |
| Session order \(\times\) Lag | 0.04 | 1 | 38 | .844 | .000 |
| Block \(\times\) Stimulation | 0.24 | 1.92 | 73.08 | .777 | .000 |
| Block \(\times\) Lag | 1.91 | 1.93 | 73.20 | .158 | .001 |
| Stimulation \(\times\) Lag | 0.31 | 1 | 38 | .584 | .000 |
| Session order \(\times\) Block \(\times\) Stimulation | 9.94 | 1.92 | 73.08 | < .001 | .007 |
| Session order \(\times\) Block \(\times\) Lag | 0.19 | 1.93 | 73.20 | .821 | .000 |
| Session order \(\times\) Stimulation \(\times\) Lag | 0.96 | 1 | 38 | .333 | .000 |
| Block \(\times\) Stimulation \(\times\) Lag | 0.31 | 1.86 | 70.75 | .718 | .000 |
| Session order \(\times\) Block \(\times\) Stimulation \(\times\) Lag | 0.53 | 1.86 | 70.75 | .580 | .000 |
3.2 Individual differences
format_study2 <- function(df) {
df %>%
select(fileno, First_Session, ends_with("_NP"), -contains("Min")) %>% # keep only relevant columns
gather(key, accuracy, -fileno, -First_Session) %>% # make long form
# split key column to create separate columns for each factor
separate(key, c("block", "stimulation", "target", "lag"), c(1,3,5)) %>% # split after 1st, 3rd, and 5th character
# convert to factors, relabel levels to match those in study 2
mutate(block = factor(block, levels = c("v", "t", "n"), labels = c("pre", "tDCS", "post")),
stimulation = factor(stimulation, levels = c("b_", "d_"), labels = c("anodal", "cathodal")),
lag = factor(lag, levels = c("_2_NP", "_4_NP", "_10_NP"), labels = c(2, 4, 10)),
First_Session = factor(First_Session, labels = c("anodal first","cathodal first"))) %>%
spread(target, accuracy) %>% # create separate columns for T2.given.T1 and T1 performance
rename(T2.given.T1 = NB, session.order = First_Session, subject = fileno)# rename columns to match those in study 2
}calc_ABmag <- function(df) {
df %>%
group_by(subject, session.order, stimulation, block) %>% # for each unique factor combination
summarise(AB.magnitude = last(T2.given.T1) - first(T2.given.T1), # subtract lags to replace data with AB magnitude,
T1.short = first(T1)) %>% # also keep T1 performance for short lag, to use as a covariate later
ungroup()
}pcorr_anodal_cathodal <- function(df) {
df %>%
# create two columns of AB magnitude change score during tDCS: for anodal and cathodal
filter(measure == "AB.magnitude") %>%
select(-baseline) %>%
spread(stimulation, change.score) %>%
ungroup() %>% # remove grouping from previous steps, as we need to modify the dataframe
select(session.order, change, anodal, cathodal) %>% # keep only relevant columns
mutate(session.order = as.numeric(session.order)) %>% # dummy code to use as covariate
nest_legacy(-change) %>% # split into two data frames, one for each comparison
# partial correlation
mutate(r = map_dbl(data, ~pcor(c("anodal","cathodal","session.order"), var(.)))) %>%
group_by(change) %>% # for each correlation
# get t-stats, df and p-value of coefficient
mutate(stats = list(as.data.frame(pcor.test(r, 1, n_distinct(df$subject))))) %>%
unnest_legacy(stats, .drop = TRUE) # unpack resulting data frame into separate column
}ABmag_study2 <- calc_ABmag(df_study2)
ABmagChange_study2 <- calc_change_scores(ABmag_study2)p_r_2 <- pcorr_anodal_cathodal(ABmagChange_study2)
r_study2 <- p_r_2$r[p_r_2$change == "tDCS - baseline"] # r-value in study 2
n_study2_pc <- n_study2-1 # one less due to additional variable in partial correlationdf_study1 <- read_tsv(here("data","AB-tDCS_study1.txt"),
col_names = TRUE, locale = locale(decimal_mark = ","),
cols(.default = col_double(),
First_Session = col_integer(),
fileno = col_character())) %>% # read study 1 data
format_study2() # format data from study 1 as in study 2ABmag_study1 <- calc_ABmag(df_study1)
ABmagChange_study1 <- calc_change_scores(ABmag_study1)
p_r_1 <- pcorr_anodal_cathodal(ABmagChange_study1)
r_study1 <- p_r_1$r[p_r_1$change == "tDCS - baseline"] # r-value in study 1
n_study1 <- n_distinct(df_study1$subject)
n_study1_pc <- n_study1-1 # one less due to additional variable in partial correlationOur main aim was to replicate London and Slagter (2021), who found a negative correlation between AB magnitude change scores (comparing the tDCS and baseline blocks) in the anodal and cathodal sessions (r(31) = -.45, 95%CI[-0.68, -0.12], p = .009). Their interpretation was that the effects of anodal and cathodal tDCS were anti-correlated: those participants that improve their performance (i.e., show a smaller AB) due to anodal tDCS tend to worsen due to cathodal tDCS, and vice versa.
We ran the same partial correlation (attempting to adjust for Session order) between the anodal and cathodal AB magnitude change scores (tDCS - baseline) on our data (Figure 3.2). However, here the resulting correlation did not go in the same direction (r(37) = .02, 95%CI[-0.30, 0.33]), and was not significant (p = .899). Or, adopting the terminology suggested by LeBel et al. (2019): we obtained no signal (the 95% confidence interval includes 0, and therefore the correlation is not significant), and our result is inconsistent (the 95% confidence interval excludes the point estimate of the correlation in London and Slagter (2021)). In the next sections, we present a number of follow-up analyses that further explore this difference in results between both studies (see the Replication analyses subsection in the Methods section).
# separate df so arrows only show on one facet
AB_arrows_y <- tibble(x = c(-.47, -.47),
xend = c(-.47, -.47),
y = c(-.05, .05),
yend = c(-.3, .3),
change = factor("tDCS - baseline", levels = levels(ABmagChange_study2$change)))
AB_labs_y <- tibble(x = c(-.50, -.50),
y = c(-.25, .25),
label = c("Smaller AB","Larger AB"),
hjust = c("left","right"),
change = factor("tDCS - baseline", levels = levels(ABmagChange_study2$change)))
corr_labels <- p_r_2 %>%
mutate(label = paste0("r(", df ,")", " = ", printnum(r,gt1=F), ", p = ", printp(pvalue)))
ABmagChange_study2 %>%
# create two columns of AB magnitude change score during tDCS: for anodal and cathodal
filter(measure == "AB.magnitude") %>%
select(-baseline) %>%
spread(stimulation, change.score) %>%
ggplot(aes(anodal, cathodal)) +
facet_wrap(~change) +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_vline(xintercept = 0, linetype = "dashed") +
geom_point(shape = 21, fill = "gray25", size = 2, color = "white", stroke = .3) +
geom_rug(colour = "gray25", alpha = .75) +
scale_x_continuous("Change in anodal session", breaks = seq(-.3,.3,.1),
labels = scales::percent_format(accuracy = 1)) +
scale_y_continuous("Change in cathodal session", breaks = seq(-.3,.3,.1),
labels = scales::percent_format(accuracy = 1)) +
coord_equal(xlim = c(-.32, .32), ylim = c(-.32, .32), clip = "off") +
annotate("segment", # x-axis arrows
x = c(-.05, .05),
xend = c(-.3, .3),
y = c(-.42, -.42),
yend = c(-.42, -.42),
arrow = arrow(angle = 20, length = unit(4,"mm"))) +
#x-axis arrow text
annotate("text", x = -.05, y = -.44, label = "Smaller AB", size = geom_text_size, hjust = "right") +
annotate("text", x = .05, y = -.44, label = "Larger AB", size = geom_text_size, hjust = "left") +
geom_segment(data = AB_arrows_y, # y-axis arrows
aes(x = x, xend = xend, y = y, yend = yend),
arrow = arrow(angle = 20, length = unit(4,"mm"))) +
geom_text(data = AB_labs_y, # y-axis arrow text
aes(x = x, y = y, label = label, hjust = hjust), size = geom_text_size, angle = 90) +
# correlation labels
geom_label(data = corr_labels, aes(label = label),
x = -.36, y = .26, hjust = "left", size = geom_text_size, label.size = 0) +
theme_minimal_grid(font_size = base_font_size, font_family = base_font_family) +
theme(strip.background = element_rect(fill = "grey90"), # facet header background
panel.spacing.x = unit(1,"lines"), # add horizontal space between facets
# move axis labels away from annotatations
axis.title.x = element_text(margin = margin(t = 17.5, r = 0, b = 0, l = 0)),
axis.title.y = element_text(margin = margin(t = 0, r = 17.5, b = 0, l = 0)))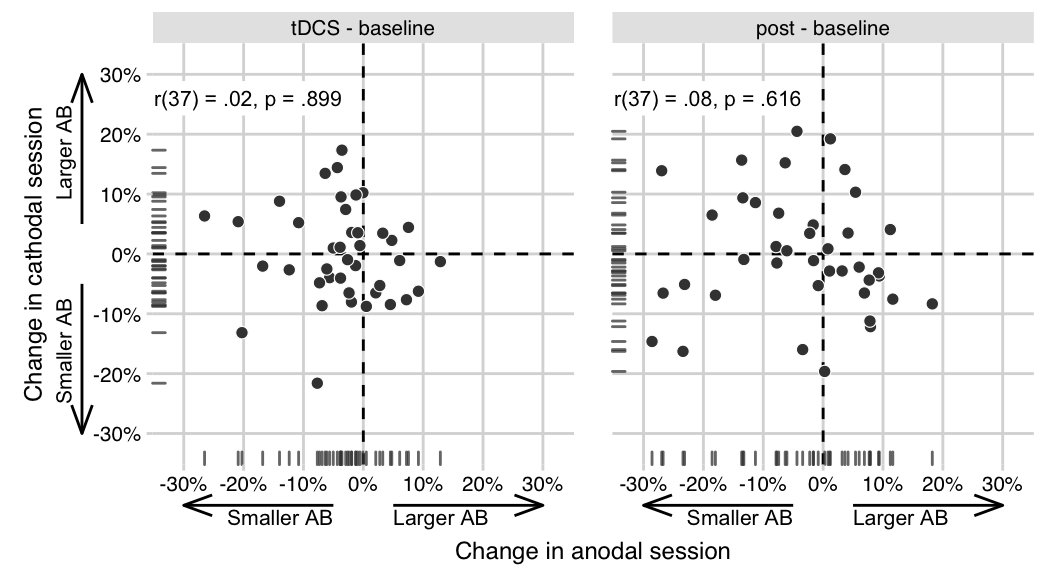
Figure 3.2: The effects of anodal and cathodal tDCS are not correlated in the present study. Data points show AB magnitude change scores (tDCS - baseline, post - baseline) for each participant in the study, in the anodal session (x-axis) and the cathodal session (y-axis). While London and Slagter (2021) found a negative partial correlation (for tDCS - baseline), suggesting opposite effects of anodal and cathodal tDCS, this effect appears to be absent here. The partial correlation coefficients (attempting to adjust for Session order) and p-values are printed in the upper left.
# remove excess top and bottom sapce
#plot.margin = unit(c(0.2, 0.2, 0.2, 0.2), "pt"))3.2.1 Is the correlation in study 2 significantly small?
SESOI_small_telescopes <- pwr.r.test(n_study1_pc, power = 0.33) # r value with 33% power in study 1
test_small_telescopes <- TOSTr(n = n_study2_pc,# equivalence test
r = r_study2,
low_eqbound_r = -SESOI_small_telescopes$r,
high_eqbound_r = SESOI_small_telescopes$r,
alpha = 0.05)London and Slagter (2021) found a medium- to large correlation (r = -.45), but the correlation we find here is much smaller (r = .02). We use equivalence testing (Daniël Lakens, Scheel, and Isager (2018); see the Equivalence tests subsection in the Methods section) to assess whether this correlation is significantly smaller than a smallest effect size of interest (SESOI). Following the “small telescopes” approach (Simonsohn 2015), we set the SESOI to \(r_{33\%}\), the correlation London and Slagter (2021) had 33% power to detect. Given their sample size of 34 participants, \(r_{33\%}\) = .27.
An inferiority test shows that the correlation here is significantly less negative than \(-r_{33\%}\) (p = .038) (Figure 3.4), although only by a small margin. The effect is therefore “statistically inferior”: the correlation does not exceed the lower equivalence bound (\(-r_{33\%}\) = -.27). By this definition, the correlation is too small (i.e. not negative enough) to be considered meaningful, indicating that we did not successfully replicate London and Slagter (2021).
3.2.2 Is the correlation in this study (study 2) different from the previous study (study 1)?
To evaluate whether the correlation in the present study (study 2) was to be expected based on London and Slagter (2021) (study 1), we constructed a 95% prediction interval (PI) (Spence and Stanley 2016), using the correlation in London and Slagter (2021) and the sample size of both studies (see the Prediction interval subsection of the Methods section).
pred_int <- pi.r(r = r_study1, n = n_study1_pc, rep.n = n_study2_pc, prob.level = 0.95)The 95% PI[-0.82, -0.05] around the original correlation (r = -.45) is very wide, so almost any negative correlation would fall within it. However, it does not include the replication result (r = .02) (Figure 3.4). Assuming the results of both studies differ only due to sampling error, the correlation observed here has a 95% chance to fall within the interval. This means the correlation in our replication study is inconsistent with the correlation in London and Slagter (2021), and thus that the replication should not be considered successful.
Another approach to quantify the difference between study 1 and 2 is to construct a replication Bayes Factor (Eric-Jan Wagenmakers, Verhagen, and Ly 2016). We use this Bayes factor to assess evidence for \(H_0\) : “the effects of anodal and cathodal tDCS are uncorrelated” relative to \(H_r\) : “the effects of anodal and cathodal tDCS are anticorrelated as in London and Slagter (2021)” (see the Replication Bayes factor subsection of the Methods section).
bf0RStudy1 <- 1/repBfR0(nOri = n_study1_pc, rOri = r_study1,
nRep = n_study2_pc, rRep = r_study2)This replication Bayes factor expresses that the data are \(BF_{0r}\) = 9.66 times more likely under \(H_0\) than under \(H_r\). This constitutes moderate to strong evidence that the effect is absent vs. consistent with London and Slagter (2021), and thus that the effect did not replicate.
3.2.3 Is the effect significant when combining study 1 and 2?
The sample size in both study 1 (n = 34) and 2 (n = 40) is on the lower end. Therefore, we might get a more accurate estimate of the size of the effect when combining both studies.
df_meta <- tibble(authors = c("London & Slagter","Reteig et al."), year = c(2021,2021),
ni = c(n_study1_pc, n_study2_pc),
ri = c(r_study1, r_study2))
# Meta-analysis
res_z <- rma(ri = ri, ni = ni, data = df_meta,
measure = "ZCOR", method = "FE", # Fisher-z tranform of r values, fixed effects method
slab = paste(authors, year, sep = ", ")) # add study info to "res" list
res_r <- predict(res_z, transf = transf.ztor) # transform back to r-values
res_zThe meta-analytic estimate of the correlation is r = -0.20, 95%CI[-0.42, 0.04], p = .094 (Figure 3.4). So, when combining the correlation from London and Slagter (2021) and the correlation observed here, the overall effect is no longer significant.
In addition, we pooled the data from both studies at the single-subject level and re-calculated the partial correlation on the combined sample (n = 74). To make the datasets as comparable as possible, we first averaged over T2|T1 accuracy at lags 2 and 4 in London and Slagter (2021), to mimic a “lag 3” condition cf. the present study (Figure 3.3). The resulting T2|T1 accuracies at lag 3 are very comparable across the two studies (study 1: M=0.65, SD=0.26; study 2: M=0.64, SD=0.24)
create_lag3_study1 <- function(df) {
df %>%
group_by(subject, session.order, block, stimulation) %>% # for each condition
# calculate lag 3 as mean of 2 and 4; keep lag 10
summarise(lag3_T2.given.T1 = (first(T2.given.T1) + nth(T2.given.T1,2)) / 2,
lag3_T1 = (first(T1) + nth(T1,2)) / 2,
lag10_T2.given.T1 = last(T2.given.T1),
lag10_T1 = last(T1)) %>%
gather(condition, score, -subject, -session.order, -block, -stimulation) %>% # gather the 4 columns we created
separate(condition, c("lag", "measure"), "_") %>% # separate lag and T1/T2|T1
mutate(lag = str_remove(lag,"lag")) %>%
mutate(lag = fct_relevel(lag, "3","10")) %>% #remake the lag factor
spread(measure, score) %>% # make a column of T1 and T2|T1
ungroup() # remove grouping to match original df from study 1
}ABmagChange_pooled <- df_study1 %>%
create_lag3_study1() %>% # create lag 3 condition in study 1
calc_ABmag() %>% # calculate AB mangnitude
calc_change_scores() %>% # calculate change from baseline
bind_rows(.,ABmagChange_study2) %>% # combine with study 2
# add a "study" column, based on subject ID formatting
mutate(study = ifelse(grepl("^pp",subject), "1", "2")) p_r_pooled <- pcorr_anodal_cathodal(filter(ABmagChange_pooled, change == "tDCS - baseline"))corr_label_pooled <- paste0("r(", p_r_pooled$df ,")", " = ",
printnum(p_r_pooled$r,gt1=F))
ABmagChange_pooled %>%
# create two columns of AB magnitude change score during tDCS: for anodal and cathodal
filter(measure == "AB.magnitude", change == "tDCS - baseline") %>%
select(-baseline) %>%
spread(stimulation, change.score) %>% { # "{" so we can access data frame below for subsetting
ggplot(., aes(anodal, cathodal, colour = study, fill = study, shape = study)) +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_vline(xintercept = 0, linetype = "dashed") +
geom_point(size = 2, color = "white", stroke = .3) +
geom_rug(data = filter(., study == 1), alpha = .75, sides = "tr") +
geom_rug(data = filter(., study == 2), alpha = .75, sides = "bl") +
scale_fill_manual(labels = c("study 1", "study 2"), values = c("#E69F00", "#56B4E9")) +
scale_colour_manual(labels = c("study 1", "study 2"), values = c("#E69F00", "#56B4E9"), guide = FALSE) +
scale_shape_manual(labels = c("study 1", "study 2"), values = c(21,24)) +
scale_x_continuous("Change in anodal session", breaks = seq(-.3,.3,.1),
labels = scales::percent_format(accuracy = 1)) +
scale_y_continuous("Change in cathodal session", breaks = seq(-.3,.3,.1),
labels = scales::percent_format(accuracy = 1)) +
coord_equal(xlim = c(-.32, .32), ylim = c(-.32, .32), clip = "off") +
annotate("segment",
x = c(-.05, .05, -.45, -.45),
xend = c(-.3, .3, -.45, -.45),
y = c(-.41, -.41, -.05, .05),
yend = c(-.41, -.41, -.3, .3),
arrow = arrow(angle = 20, length = unit(4,"mm"))) +
annotate("text", x = -.25, y = -.43, label = "Smaller AB", size = geom_text_size, hjust = "left") +
annotate("text", x = .25, y = -.43, label = "Larger AB", size = geom_text_size, hjust = "right") +
annotate("text", x = -.47, y = -.25, label = "Smaller AB",
size = geom_text_size, angle = 90, hjust = "left") +
annotate("text", x = -.47, y = .25, label = "Larger AB",
size = geom_text_size, angle = 90, hjust = "right") +
annotate("label", label = corr_label_pooled,
x = -.29, y = .26, hjust = "left", size = geom_text_size, label.size = 0) +
theme_minimal_grid(font_size = base_font_size, font_family = base_font_family) +
theme(legend.title = element_blank(), legend.background = element_blank(),
legend.position = "top", legend.direction = "horizontal",
axis.title.x = element_text(margin = margin(t = 17.5, r = 0, b = 0, l = 0)),
axis.title.y = element_text(margin = margin(t = 0, r = 15, b = 0, l = 0)))
}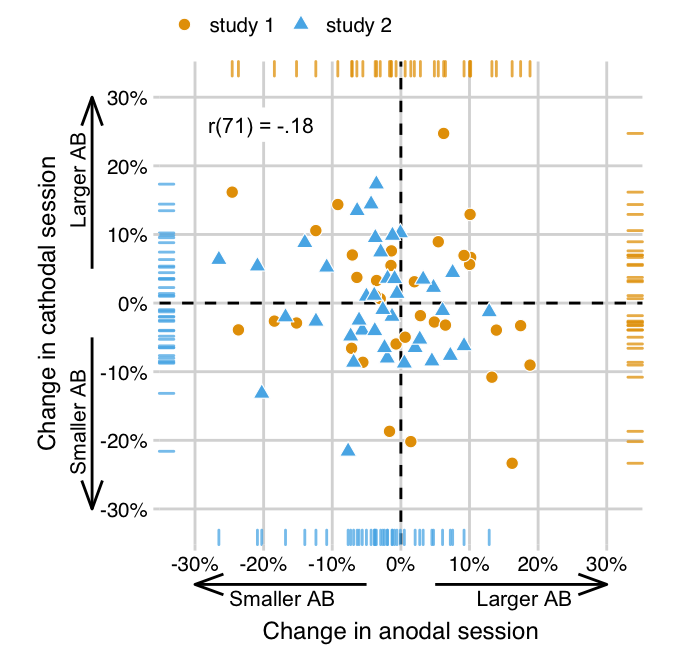
Figure 3.3: The effects of anodal and cathodal tDCS are also not correlated when pooling data from both studies. As in Figure 3.2, data points show AB magnitude change scores (tDCS - baseline) in the anodal session (x-axis) and the cathodal session (y-axis), but now for each participant in London and Slagter (2021) (study 1) and the present study (study 2). While London and Slagter (2021) found a negative partial correlation, suggesting opposite effects of anodal and cathodal tDCS, this effect appears to be absent when based on the combined data of both studies. The partial correlation coefficient (attempting to adjust for Session order) is printed in the upper left.
The partial correlation based on the pooled data is r(71) = -.18. Thus, the correlation across a combination of both samples is a lot smaller than in London and Slagter (2021), and slightly smaller still than the meta-analytic estimate that included the original correlation from London and Slagter (2021) (Figure 3.4).
rep_plot_df <- bind_cols(tibble::tribble(
~analysis, ~estimate, ~source,
"London & Slagter (2021)", r_study1, "Study 1",
"Present study", r_study2, "Study 2",
"Equivalence test", r_study2, "Study 2",
"Prediction interval", r_study1, "Study 1",
"Meta-analysis", res_r$pred, "NA",
"Pooled data", p_r_pooled$r, "NA"
), tibble::tribble(
~int_min, ~int_max, ~int_type,
CIr(r_study1,n_study1_pc,.95)[1], CIr(r_study1,n_study1_pc,.95)[2], "95% CI",
CIr(r_study2,n_study2_pc,.95)[1], CIr(r_study2,n_study2_pc,.95)[2], "95% CI",
test_small_telescopes$LL_CI_TOST, test_small_telescopes$UL_CI_TOST, "90% CI",
pred_int$lower_prediction_interval, pred_int$upper_prediction_interval, "95% PI",
res_r$ci.lb, res_r$ci.ub, "95% CI",
CIr(p_r_pooled$r,n_study1+n_study2_pc,.95)[1], CIr(p_r_pooled$r,n_study1+n_study2_pc,.95)[2], "95% CI"
)) %>%
mutate( # reorder levels for plot
analysis = factor(analysis,
levels = c("London & Slagter (2021)", "Present study", "Equivalence test",
"Prediction interval", "Meta-analysis", "Pooled data")),
label = paste0("r = ", printnum(estimate,gt1=F), ", ",
int_type, " [",printnum(int_min,gt1=F), ", ", printnum(int_max,gt1=F), "]")
) # create labels for plotggplot(rep_plot_df, aes(estimate,analysis)) +
geom_vline(xintercept = c(0,r_study1,r_study2), linetype = "dashed",
color = c("black", "#E69F00", "#56B4E9")) +
geom_errorbarh(aes(y = analysis, xmin = int_min, xmax = int_max), height = .25, color = "gray50") +
geom_point(shape = 23, aes(fill = source), size = 2) +
geom_point(x = -SESOI_small_telescopes$r, y = 4, shape = 4, size = 1, color = "black") +
geom_label(x = .45, aes(y = analysis, label = label), hjust = "left",
size = geom_text_size, label.size = 0) +
scale_fill_manual(values = c("gray", "#E69F00", "#56B4E9"), guide = FALSE) +
scale_y_discrete("", limits = rev(levels(rep_plot_df$analysis))) + # reverse order to match levels in data frame
scale_x_continuous("correlation coefficient", c("-1" = -1, "-.8" = -0.8, "-.6" =
-0.6, "-.4" = -0.4, "-.2" = -0.2,
"0" = 0, ".2" = 0.2, ".4" = 0.4, ".6" = 0.6,
".8" = 0.8, "1" = 1)) +
coord_cartesian(c(-1,1), clip = "off") +
theme_minimal_vgrid(font_size = base_font_size, font_family = base_font_family) +
theme(axis.line = element_blank(), axis.ticks = element_blank(),
plot.margin = unit(c(1,3,1,.25), "lines"))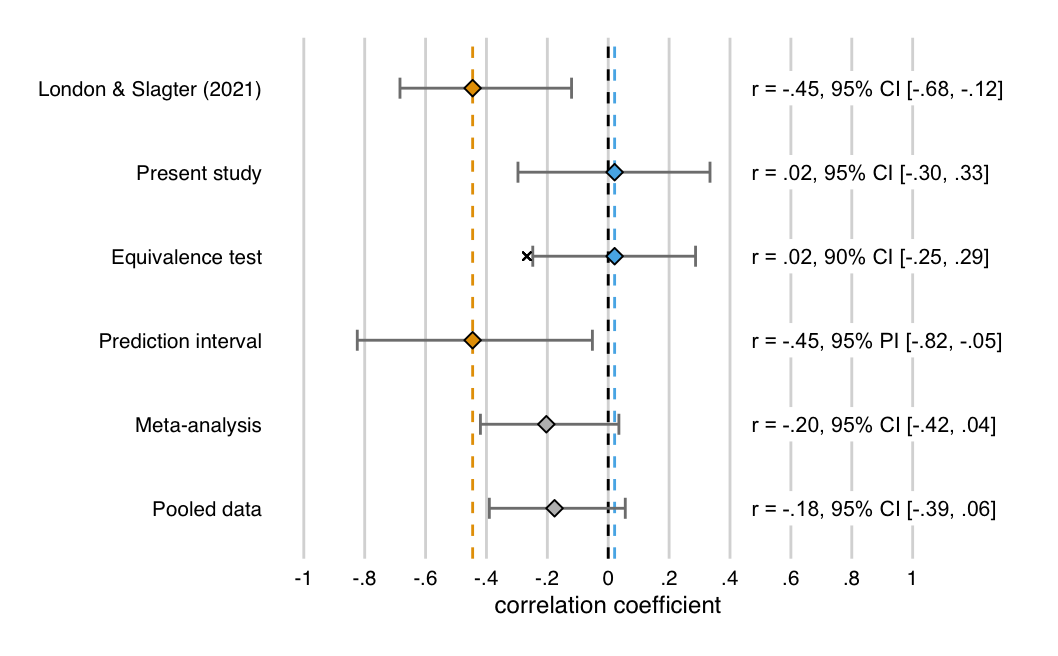
Figure 3.4: Summary of all the replication analyses (with exception of the replication Bayes Factor). The first two rows show the partial correlation (attemtping to adjust for Session order) between the AB magnitude change scores (tDCS - baseline) in the anodal and cathodal sessions, for study 1 (London and Slagter 2021) (in yellow) and the present study (in blue). The first is significantly negative, the second is slightly positive and not significant, because its 95% confidence interval (CI) overlaps with zero. The third row shows the 90% CI around the correlation in the present study. Because this interval does not overlap with the “small telescopes” effect size, (indicated by the x: \(-r_{33\%}\) = -.27), this correlation is significantly smaller. The fourth row shows the 95% prediction interval (PI) around the correlation in London and Slagter (2021). Because this interval does not overlap with the correlation in the present study, both correlations are not consistent. The final two rows show the overall effect when the two correlations are meta-analyzed, and when one correlation is computed over the pooled data from both studies. Neither are significant (95% CI overlaps with zero). Thus, our replication analyses all suggest that we failed to replicate London & Slagter (2021), and when the results are examined in combination, no evidence in support of a negative relationship between the AB magnitude change scores (tDCS - baseline) in the anodal and cathodal sessions is obtained.
In sum, all the analyses we conducted seem to support the same conclusion: that the current study is not a successful replication of London and Slagter (2021), and that therefore the purported opposing effect of anodal and cathodal tDCS on the attentional blink within individuals is called into question.
4 Discussion
Our recent study (London and Slagter 2021) was the first to uncover potential individual differences in the effect of tDCS on the AB. This original study revealed a negative correlation between the effects of anodal and cathodal tDCS on T2|T1 accuracy across individuals individuals (in the absence of a group-level effect of tDCS). This analysis suggested an interesting pattern of individual differences in response to tDCS: those that tended to benefit from anodal tDCS (i.e., whose AB became smaller compared to baseline) would tend to worsen during cathodal tDCS, and vice versa. This finding seemed plausible given the substantial and well-documented individual differences in both the AB (Willems and Martens 2016) and the effects of tDCS (Krause and Cohen Kadosh 2014).
We conducted a replication study, and again found no effect of tDCS at the group level. However, in contrast to our prior work (London and Slagter 2021), the correlation between the AB magnitude change scores (tDCS - baseline) in the anodal and cathodal sessions here is not significant, and not in the same direction. We therefore also computed several statistical measures of replication success focused on the negative correlation between anodal and cathodal tDCS. As discussed in more detail below, the field of electrical brain stimulation is characterized by inconsistent findings across studies. It is hence important that researchers in this field also start to incorporate methods that permit quantification of replication success. It is our hope that the overview of main, complementary analyses that researchers can use to maximize the evidential value from negative findings, provided here, will serve as a guideline for future studies.
The measures of replication success showed that in our study the observed correlation is smaller than we found previously in London and Slagter (2021), and than the smallest correlation they could have reasonably detected (i.e., an equivalence test for the lower bound of \(r_{33\%}\) (Simonsohn 2015) was significant). The difference between the two studies is greater than expected based on sampling error alone (i.e., the correlation in the present study falls outside of the 95% prediction interval). Further, the data provide moderate to strong evidence for the null hypothesis of zero correlation compared to the alternative that the correlation is as in the original study (London and Slagter 2021) (i.e., we found a replication Bayes factor in favor of the null hypothesis of ~10). Finally, combining both studies yields a smaller and non-significant correlation (both in a meta-analysis and by pooling the data).
The overall picture is consistent: all measures indicate that the present study is not a successful replication of our original study (London and Slagter 2021). But because both studies were similar in design and sample size, it is not warranted to dismiss the previous findings. Our analysis revealed substantial variation between both estimates of the effect, and so the conclusion whether tDCS is effective should not be based on any single study, nor on only a single replication study (Hedges and Schauer 2019). In any series of studies, one should expect to sometimes not find a significant result, purely due to random variation—even if there is a true effect (Amrhein, Trafimow, and Greenland 2019).
Still, the marked difference in results of both studies is surprising: they are similar enough that the present study could be considered a direct replication (Zwaan et al. 2018) of the first study (London and Slagter 2021). We used the exact same electrode montage and tDCS parameters, followed the same experimental design (Figure 2.1), ran the experiment in the same location with the same participant population, and used a virtually identical task. Nevertheless, there are some discrepancies between the studies that could have contributed to the different outcome (see Table 4.2 for a full list of the differences).
The most important difference is that in the previous study (London and Slagter 2021), T2 was presented at lags 2, 4, and 10, whereas we now used lags 3 and 8. This means that AB magnitude (the difference in T2|T1 accuracy between the shortest and longest lag) was on average smaller in the present study. We introduced the change for precisely this reason: to have about as many trials for the EEG analyses in which T2 was seen vs. missed, we needed the AB to be smaller. But this increase in average T2|T1 accuracy may have also reduced the between-subject variability that is essential for analyses that capitalize on individual differences. Indeed, from Figure 3.3 it seems that the previous sample (London and Slagter 2021) had a larger spread, at least in the change scores for AB magnitude.
Though the change in lags is probably the most important, the concurrent EEG measurement did introduce other differences as well. Each session took longer to complete, because the EEG setup required extra time, and the pace of the task was slowed down with longer inter-stimulus intervals. Finally, the current flow could have changed due to the presence of the EEG cap and electrodes, as well as the use of conductive paste instead of saline solution.
At the group level, our results are in agreement (London and Slagter 2021): we find no differential effects of anodal and cathodal tDCS on the AB. However, another study (Sdoia et al. 2019) did report a group-level effect of tDCS on the AB, but this study used different stimulation parameters and was fairly small (see our previous paper (London and Slagter 2021) for a more extensive discussion of the differences). At least with our AB task and fairly standard electrode montage and stimulation parameters (Santarnecchi et al. 2015), the AB does not appear to be very amenable to tDCS over the lDLPFC. Our null results are consistent with recent reviews and meta-analyses highlighting there is little evidence that prefrontal tDCS can be used to enhance cognition (Medina and Cason 2017); or if so, that its effects on attention (Reteig et al. 2017) and cognition more generally (Tremblay et al. 2014) are difficult to predict, rather small (Dedoncker et al. 2016), and restricted to a limited subset of outcome measures and stimulation parameters (Boer et al. 2021; Imburgio and Orr 2018).
Interpreting null results is always difficult, especially in brain stimulation studies (Graaf and Sack 2018). Ultimately, a myriad of possible underlying explanations may apply, most of which we have no direct access to. For one, we cannot be sure that the current density in the lDLPFC reached sufficient levels (Kim et al. 2014; Opitz et al. 2015) based on our montage alone. More precise targeting of the stimulation towards the lDPLFC (Datta et al. 2009) and modeling of the current flow (Berker, Bikson, and Bestmann 2013; Karabanov et al. 2019) could provide some more confidence. Still, it would be difficult to verify that anodal tDCS and cathodal tDCS indeed had an opposite effect on cortical excitability (Bestmann, de Berker, and Bonaiuto 2015; Bestmann and Walsh 2017). This assumption holds in many cases, and would provide a plausible explanation (Krause and Cohen Kadosh 2014) for the negative correlation we originally found (London and Slagter 2021) . But ideally, it should be validated with direct measures of cortical excitability. Such measures are hard to obtain, although some recent studies suggest that combining tDCS with magnetic resonance spectroscopy can be used for this purpose (H. L. Filmer et al. 2019; Antonenko et al. 2019; Talsma et al. 2018). Combining tDCS with MRI may also help predict individual differences in stimulation efficacy. One recent study found that individual variability in the cortical thickness of left prefrontal cortex accounted for almost 35% of the variance in stimulation efficacy among subjects (Hannah L. Filmer et al. 2019).
It is also possible that we do not find an effect because the studies did not have sufficient statistical power (Minarik et al. 2016). Especially for the individual differences analyses, the sample size in both studies is on the lower end. For example, to detect a medium-sized correlation (r = 0.3) with 80% power, the required sample size is n = 84. We do approach this sample size when combining both studies (n = 74). Also, the correlation in London and Slagter (2021) was larger (r = -0.45), but we cannot have much confidence in the precision of this estimate: : the 95% confidence interval is so wide (-0.68 to -0.12) that it is consistent with a large range of effect sizes, and therefore almost unfalsifiable (R. Morey and Lakens 2016). To estimate the size of a medium correlation (r = 0.3) within a narrower confidence band (± 0.15 with 90% confidence), a sample size of n = 134 would be required (Schönbrodt and Perugini 2013). Although our analyses suggest that the correlation is small if anything, this means we cannot accurately estimate how small—even with the combined sample.
These are all decisions to be made at the design stage, which can increase the value of a null result (Graaf and Sack 2018). However, after the data are in, additional tools are available to increase the value of a null result (Harms and Lakens 2018), especially in the case of a replication study (Simonsohn 2015), which we have demonstrated here.
We hope our paper provides inspiration for others in the fields of brain stimulation and cognitive neuroscience. Many speak of a crisis of confidence (Héroux et al. 2017) and fear that the current literature is lacking in evidential value (Medina and Cason 2017). This is certainly not a unique development, as these sentiments (Baker 2015) and low rates of replication abound in many research areas (Open Science Collaboration 2015; Camerer et al. 2018; Klein et al. 2018). But it is perhaps aggravated by the fact that the brain stimulation field has not matured yet (Parkin, Ekhtiari, and Walsh 2015). At the same time, this also leaves room for the field to improve, and more work is necessary to determine the potential of electrical brain stimulation (Hannah L. Filmer, Mattingley, and Dux 2020).
To make sure the literature accurately reflects the efficacy of the technique, it is crucial to combat publication bias. Positive results are heavily over-represented in most of the scientific literature, (Ferguson and Heene 2012; Franco, Malhotra, and Simonovits 2014; Fanelli 2012), which has recently prompted a call to brain stimulation researchers to also publish their null results.6 Preregistration and registered reports are other important methods to combat publication bias that the field of electrical brain stimulation should embrace (see e.g., Horne et al. (2021)). Publishing null results and replication studies—and making the most of their interpretation—is crucial to better this situation.
Acknowledgements
This work was supported by a Research Talent Grant from the Netherlands Organization for Scientific Research (NWO) (452-10-018, to HAS and KRR). We thank Raquel London for sharing all her experience and materials, as well as Daphne Box and Esther van der Giessen for their assistance in data collection.
References
Supplementary material
tDCS_AE <- read_csv2(here("data", "tDCS_AE.csv"), col_names = TRUE, progress = FALSE, col_types = cols(
session = readr::col_factor(c("first", "second")),
stimulation = readr::col_factor(c("anodal", "cathodal"))))# Make long form data frame of sensation intensity
intensity <- tDCS_AE %>%
select(everything(), -contains("conf"), -notes) %>% # drop other columns
gather(sensation, intensity, itching:nausea) # make long form
# Make long form data frame of sensation confidence
confidence <- tDCS_AE %>%
select(contains("conf"), subject, session, stimulation) %>%
gather(sensation, confidence, conf.itching:conf.nausea) %>%
# get rid of "conf." prefix so it matches the sensation intensity table
mutate(sensation = str_replace(sensation, "conf.", ""))
int_conf <- full_join(intensity,confidence) %>%
# gather confidence/intensity to make one plot for each
gather(measure, rating, intensity, confidence) %>%
mutate(measure = factor(measure, levels = c("intensity", "confidence")))tbl_int_anodal <- intensity %>%
filter(stimulation == "anodal") %>%
count(sensation, intensity) %>%
spread(intensity, n) %>%
replace(is.na(.), 0) %>%
mutate_if(is.double, as.integer)
tbl_int_cathodal <- intensity %>%
filter(stimulation == "cathodal") %>%
count(sensation, intensity) %>%
spread(intensity, n) %>%
replace(is.na(.), 0) %>%
mutate_if(is.double, as.integer)
tbl_conf_anodal <- confidence %>%
filter(stimulation == "anodal") %>%
count(sensation, confidence) %>%
spread(confidence, n) %>%
replace(is.na(.), 0) %>%
mutate_if(is.double, as.integer)
tbl_conf_cathodal <- confidence %>%
filter(stimulation == "cathodal") %>%
count(sensation, confidence) %>%
spread(confidence, n) %>%
replace(is.na(.), 0) %>%
mutate_if(is.double, as.integer)
ae_colnames <- c(" ",
"none", "a little", "moderate", "strong", "very strong",
"n/a", "unlikely", "possibly", "likely", "very likely")
bind_rows(full_join(tbl_int_anodal, tbl_conf_anodal, by = "sensation"),
full_join(tbl_int_cathodal, tbl_conf_cathodal, by = "sensation")) %>%
kable(col.names = ae_colnames, booktabs = TRUE,
caption = "Number of reports of tDCS side effects") %>%
kable_styling(bootstrap_options = "striped",
latex_options = "scale_down") %>%
add_header_above(c(" " = 1, "Intensity rating" = 5, "Confidence rating" = 5)) %>%
pack_rows(index = c("anodal session" = 8, "cathodal session" = 8)) %>%
footnote(number = c(
"Intensity rating: To which degree were the following sensations present during stimulation?",
"Confidence rating: To which degree do you believe this was caused by the stimulation?"))| none | a little | moderate | strong | very strong | n/a | unlikely | possibly | likely | very likely | |
|---|---|---|---|---|---|---|---|---|---|---|
| anodal session | ||||||||||
| burning | 23 | 11 | 8 | 4 | 0 | 23 | 0 | 2 | 7 | 14 |
| dizziness | 43 | 3 | 0 | 0 | 0 | 43 | 1 | 2 | 0 | 0 |
| fatigue | 22 | 9 | 12 | 2 | 1 | 24 | 13 | 8 | 1 | 0 |
| headache | 32 | 9 | 3 | 1 | 1 | 34 | 1 | 10 | 1 | 0 |
| itching | 18 | 17 | 7 | 4 | 0 | 18 | 1 | 4 | 8 | 15 |
| nausea | 43 | 2 | 1 | 0 | 0 | 43 | 1 | 1 | 1 | 0 |
| pain | 41 | 3 | 2 | 0 | 0 | 40 | 1 | 0 | 4 | 1 |
| tingling | 11 | 21 | 9 | 5 | 0 | 11 | 0 | 4 | 12 | 19 |
| cathodal session | ||||||||||
| burning | 26 | 9 | 5 | 2 | 1 | 25 | 0 | 1 | 7 | 10 |
| dizziness | 40 | 2 | 0 | 1 | 0 | 39 | 0 | 2 | 1 | 1 |
| fatigue | 15 | 13 | 6 | 8 | 1 | 18 | 12 | 9 | 4 | 0 |
| headache | 30 | 7 | 4 | 2 | 0 | 31 | 0 | 8 | 2 | 2 |
| itching | 18 | 14 | 9 | 2 | 0 | 18 | 0 | 0 | 15 | 10 |
| nausea | 41 | 2 | 0 | 0 | 0 | 40 | 0 | 2 | 0 | 1 |
| pain | 37 | 4 | 0 | 2 | 0 | 36 | 0 | 1 | 3 | 3 |
| tingling | 5 | 25 | 11 | 2 | 0 | 5 | 0 | 1 | 15 | 22 |
| 1 Intensity rating: To which degree were the following sensations present during stimulation? | ||||||||||
| 2 Confidence rating: To which degree do you believe this was caused by the stimulation? | ||||||||||
ae_plot <- ggplot(int_conf, aes(x = rating, fill = stimulation)) +
facet_grid(measure ~ fct_reorder(sensation, rating,
.fun = function(x) sum(x > 0, na.rm = TRUE), .desc = TRUE)) +
geom_bar(position = "stack") +
stat_bin(binwidth = 1, geom = "text", size = geom_text_size,
aes(label = ..count..), position = position_stack(vjust = 0.25), check_overlap = TRUE) +
scale_fill_manual(values = c("#F25F5C", "#4B93B1")) +
xlim(0.5,4.5) + # exclude "0" ratings that were not present
scale_y_continuous("number of sessions reported", limits = c(0,sum(!is.na(tDCS_AE$stimulation))),
# bound plot at max number of ratings
breaks = c(0,15,30,45,60,75,sum(!is.na(tDCS_AE$stimulation)))) +
theme_minimal_hgrid(font_size = base_font_size, font_family = base_font_family) +
theme(legend.background = element_blank(), legend.position = "top",
legend.direction = "horizontal", legend.title = element_blank()) +
theme(strip.background = element_rect(fill = "grey90"), panel.spacing.y = unit(1,"lines"),
axis.ticks.x = element_line(), axis.ticks.length = unit(.25,"lines"))
suppressWarnings(print(ae_plot))![tDCS adverse events. Number of reports out of 89 sessions (either anodal or cathodal tDCS). Top row shows intensity ratings [little, moderate, strong, very strong]; bottom row shows participant’s confidence that event was related to tDCS [unlikely, possibly, likely, very likely]. Adverse events are sorted in descending order of number of reports (for very rare events (five reports or fewer for a given polarity), some text counts have been removed to prevent overlap).](AB-tDCS_paper_files/figure-html/fig-tDCS-AE-1.png)
Figure 4.1: tDCS adverse events. Number of reports out of 89 sessions (either anodal or cathodal tDCS). Top row shows intensity ratings [little, moderate, strong, very strong]; bottom row shows participant’s confidence that event was related to tDCS [unlikely, possibly, likely, very likely]. Adverse events are sorted in descending order of number of reports (for very rare events (five reports or fewer for a given polarity), some text counts have been removed to prevent overlap).
| Difference | Study 2 | Study 1 | Motivation |
|---|---|---|---|
| Sample: size | 40 | 34 | |
| Sample: age | Mean: 20.94, SD: 4.25 | Mean: 22.4, SD: 2.8 | |
| Sample: gender | 29 female (73%) | 20 female (59%) | |
| Design: concurrent measurements | EEG | None | |
| Design: inter-session interval | 1 week | min. 48 hours | Increase similarity between sessions; longer washout time |
| Design: trials per 20-minute block | Short-lag trials: M=130, SD=17; Long-lag trials: M=65; SD=9 | Short-lag trials:40; Long-lag trials: 40 | Allow as many trials as possible in 20 minutes by making the task self-paced |
| Task: RSVP stream | 15 letters | 17 letters | Shorten the total length of a trial, to allow completion of more trials |
| Task: inter-stimulus interval | 1750 ms, + 1000 ms | 480 ms | Allow EEG responses to return to baseline |
| Task: priming condition | Absent | Present | Remove priming condition as it is orthogonal to main contrast, and showed no effects in London and Slagter (2021) |
| Task: attentional blink conditions | lag 3, 8 | lag 2, 4, 10 | Increase proportion of trials where T2 was seen, for EEG analysis |
| tDCS: conductive medium | Conductive paste | Saline solution | Prevent bridging EEG electrodes with (spreading) saline solution |
We also aimed to examine the neurophysiological mechanisms underlying the individual differences in response to tDCS using EEG (Krause and Cohen Kadosh 2014; Li, Uehara, and Hanakawa 2015; Harty, Sella, and Cohen Kadosh 2017). However, since we did not replicate the behavioral effect of tDCS on the AB as in our original study (London and Slagter 2021), we were unable to fulfill this aim.↩︎
We, furthermore, used the R-packages BayesFactor [Version 0.9.12.4.2; R. D. Morey and Rouder (2018)], broom [Version 0.7.4.9000; Robinson, Hayes, and Couch (2021)], cowplot [Version 1.1.1; Wilke (2020)], emmeans [Version 1.5.4; Lenth (2021)], here [Version 1.0.1; Müller (2020)], kableExtra [Version 1.3.2; Zhu (2021)], knitr [Version 1.31; Xie (2015)], papaja [Version 0.1.0.9997; Aust and Barth (2020)], psychometric [Version 2.2; Fletcher (2010)], pwr [Version 1.3.0; Champely (2020)], and tidyverse [Version 1.3.0; Wickham et al. (2019)].↩︎
Research Topic in Frontiers, “Non-Invasive Brain Stimulation Effects on Cognition and Brain Activity: Positive Lessons from Negative Findings”: https://www.frontiersin.org/research-topics/5535/non-invasive-brain-stimulation-effects-on-cognition-and-brain-activity-positive-lessons-from-negativ↩︎